
Leveraging Iceberg as an Open Data Lake Format
As a cloud-native solution, Iceberg enables data storage in an open format accessible through open standards-based interfaces, making it flexible and adaptable. This article discusses the rich feature set that comes with Iceberg and how Cloudera provides vendor support through its product stack.
What is the “Open Data Lake”?
As a general concept, “Open Data Lake” refers to data stored in an open format and accesible through open standards-based interfaces. An open data lake is a large-scale, flexible, and distributed data storage system that enables storing vast amounts of raw and unprocessed data in its native format. Unlike traditional data warehouses, which impose a structured schema on the data before storage, data lakes accept data in the original form, making it possible for the user to store diverse data types (e.g. structured/unstructed data, etc.).
While several companies have provided vendor support to the concept, as a whole, the key characteristics of an open data lake are:
Flexibility: Open data lakes can store data from various sources without requiring data transformation or schema alterations. This flexibility allows organizations to accommodate new data sources easily.
Scalability: Data lakes are designed to handle massive volumes of data. They can scale horizontally by adding more nodes to the system, enabling seamless expansion as data volumes grow.
Cost-Effectiveness: Open data lakes often use commodity hardware and open-source software, which can be more cost-effective than traditional data warehousing solutions.
Data Variety: Data lakes can store a wide variety of data types, including structured data (e.g., relational databases), semi-structured data (e.g., JSON, XML), and unstructured data (e.g., documents, images, videos).
Support for Big Data Processing: Open data lakes work well with big data processing frameworks like Apache Hadoop and Apache Spark, enabling large-scale data analysis and processing.
Schema-on-Read: Unlike traditional databases that enforce a schema before data ingestion (schema-on-write), data lakes adopt a “schema-on-read” approach. The schema is applied when the data is read or queried, allowing for more flexibility and dynamic data exploration.
Data Governance and Security: Open data lakes often provide tools and mechanisms for data governance, access control, and security, ensuring that sensitive data is properly protected.
Integration with Data Tools and Analytics Platforms: Data lakes can integrate with various data processing and analytics tools, making it easier for data engineers, data scientists, and analysts to work with the data.
Open Standards and Interoperability: Open data lakes adhere to open standards, making data interchange and sharing across different systems and platforms more straightforward.
How does Iceberg come into the picture?
Apache Iceberg was born out of a project at Netflix called “Iceberg.” Netflix was using Apache Hive as their primary data processing engine to work with data stored in their data lake; however, as their data lake grew in size and complexity, they encountered several issues related to data management, table partitioning, metadata management, and data consistency. To address challenges of effective table metadata management, data consistency, ACID semantics, and more efficient data management, Netflix developed the Iceberg format and library. In 2018, the team open-sourced Iceberg to encourage broader adoption and community collaboration. Since then, it has gained popularity as a powerful tool for managing large-scale data in data lakes, and it’s widely used in the big data ecosystem for its robustness, performance, and data governance features.
How does Iceberg differentiate itself from other open-source formats?
Apache Iceberg differentiates itself from other table formats, particularly traditional file formats like Apache Parquet and Apache ORC, by offering several unique features and capabilities that address some common limitations in the management and processing of data in data lakes. Rather than aiming to replace file formats like Parquet or ORC, it builds on top of them and complements their functionalities, offering additional features that are especially valuable for large-scale data management, data governance, and data versioning in data lake environments. Here are some key differences:
Schema Evolution and Data Evolution Support: Iceberg provides native support for schema evolution, allowing users to modify the table schema over time without breaking data compatibility. This feature is especially useful when dealing with evolving data structures in a data lake. Other formats might not handle schema evolution as seamlessly, requiring additional workarounds.
Time Travel and Snapshot Isolation: Iceberg introduces time travel capabilities, enabling users to access historical versions of data, view changes, and recover data from previous states. It allows for more robust auditing, debugging, and data recovery. Traditional formats like Parquet and ORC lack built-in support for time travel.
Transaction Support and ACID Semantics: Iceberg provides support for atomic transactions with ACID (Atomicity, Consistency, Isolation, Durability) semantics, ensuring data consistency and integrity in the face of concurrent operations. Most traditional file formats lack such transactional guarantees.
Metadata Management: Iceberg maintains extensive metadata about the table, including schema history, table snapshots, and other important information. This metadata management enables efficient data pruning, which improves query performance by skipping irrelevant data files during execution.
Partitioning Flexibility: Iceberg supports hierarchical and composite partitioning, providing more flexibility in how data is partitioned, organized, and accessed. This can lead to more optimized queries and faster data retrieval.
Compatibility and Interoperability: Iceberg is designed to work with multiple processing engines and platforms, providing better interoperability. It allows users to work with the same table using different engines like Apache Spark, Apache Hive, and Presto, among others.
Simplified Deletes and Updates: Iceberg allows for more straightforward data deletes and updates in a data lake environment, overcoming some limitations of other formats when it comes to handling updates or deletions of records.
Metadata Snapshotting: Iceberg supports snapshotting of metadata, which helps capture a consistent view of the table at a given point in time. This ensures that metadata changes, such as schema updates, are isolated from ongoing queries.
Understanding How Iceberg Works Under the Hood
Iceberg may be understood through the 3 major components of its underlying architecture: (1) the Catalog layer, (2) the Metadata layer, and (3) the Data layer. The Catalog layer serves as the interface to manage tables, the Metadata layer holds structural information and historical changes, and the Data layer stores the actual data files in an efficient and immutable manner. Together, these layers form the foundation of Apache Iceberg, enabling advanced data management and analytical capabilities in data lake environments.
The illustration I’ve drawn below helps the reader understand exactly what each part does:
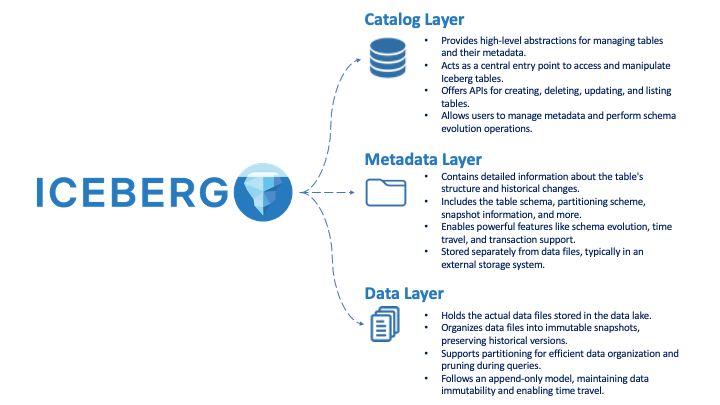
Getting started with Iceberg
In Cloudera Data Platform (CDP), Apache Iceberg is supported as a cloud-native, high-performance open table format for organizing large-scale analytic datasets in file systems or object stores. CDP offers broad support for Iceberg across its data services, including Cloudera Data Engineering (CDE), Cloudera Data Warehouse (CDW), Cloudera Public Cloud Data Hub, Apache Atlas, Cloudera DataFlow (CDF), and more. Iceberg v1 and v2 integrations are available for Spark, Hive, Impala, and Flink. Iceberg provides several advantages, such as high throughput reads, time travel queries, and efficient querying with high concurrency. It supports ACID transactions, atomic and isolated database transaction properties, and features a sophisticated partitioning technique for performance optimization. Iceberg uses multiple layers of metadata files for data pruning and relieves pressure on the Hive metastore, enabling rapid scaling without performance degradation. The integration of Apache Iceberg in CDP empowers users to build open data lakehouse architectures, facilitating multi-function analytics and large-scale end-to-end pipelines with unified platforms for structured and unstructured data.
Want to Read More and Get Started?
If any of the features I discussed sound interesting to you, I would encourage you to check out the links below and get hands on.
