
Adopting an Open Data Lakehouse with NiFi
Iceberg, a prominent player in Open Data Lakehouse architectures, is seamlessly integrated into NiFi, offering a unified platform for managing diverse data streams while ensuring schema evolution and data integrity, making it a robust solution for complex data ingestion and egress in dynamic environments. Here, I demonstrate how you can adopt a NiFi flow to do this in under 5 minutes.
Adopting an Open Data Lakehouse for Data in Motion
Coming from the financial sector where most of our use cases tended towards ETL and heavy data processing, I was suprised to learn how many use cases were built around DiM (“Data in Motion”) tooling. These tools are designed primarily to aid in moving data from point A to point B, but under the hood, they can do so much more. Notably, Cloudera Data Flow, underpinned by the Apache NiFi framework, commands a substantial market presence, and as such will be the one I reference throughout the article. Truthfully, I am not sure how many other players are out there given NiFi is really the only one I see being discussed in the data community. My first introduction to NiFi has been primarily as a tool for data replication and data movement where the primary sources were data in Production cluster A being copied to its counterpart in Disaster Recovery (“DR”) cluster B. NiFi, as a technology, represents a robust data integration platform that excels in orchestrating the seamless movement, transformation, and secure transfer of data across various sources and targets. Its intuitive drag-and-drop interface empowers the user to design, automate, and monitor complex data flows, making it an invaluable asset for efficient data management and integration tasks.
Iceberg, as I discussed two articles ago, represents one of the three major players in Open Data Lakehouse architectures, and is integrated into NiFi in a way that helps illustrate my broader point about adoption. The Iceberg open data lakehouse architecture offers a compelling advantage by providing a unified platform for managing diverse data streams. Iceberg’s schema evolution capabilities accommodate changing data structures, ensuring seamless integration of new sources without disrupting ongoing operations. This architecture enables efficient querying across varied data formats and sources while maintaining data integrity, making it a robust solution for handling the complexity of data ingestion and egress within a dynamic environment. As I have shown in the diagram below, NiFi is just one of several products in the Cloudera stack that can utilize an Iceberg table for advanced data analysis. While the remaining context of this article is geared towards how to use NiFi (and Impala through CDW) for getting a data flow up and running quickly using an open data lakehouse architecture, I think its important to call out some of these other products which the data scientist may be using as part of their toolkit as well.
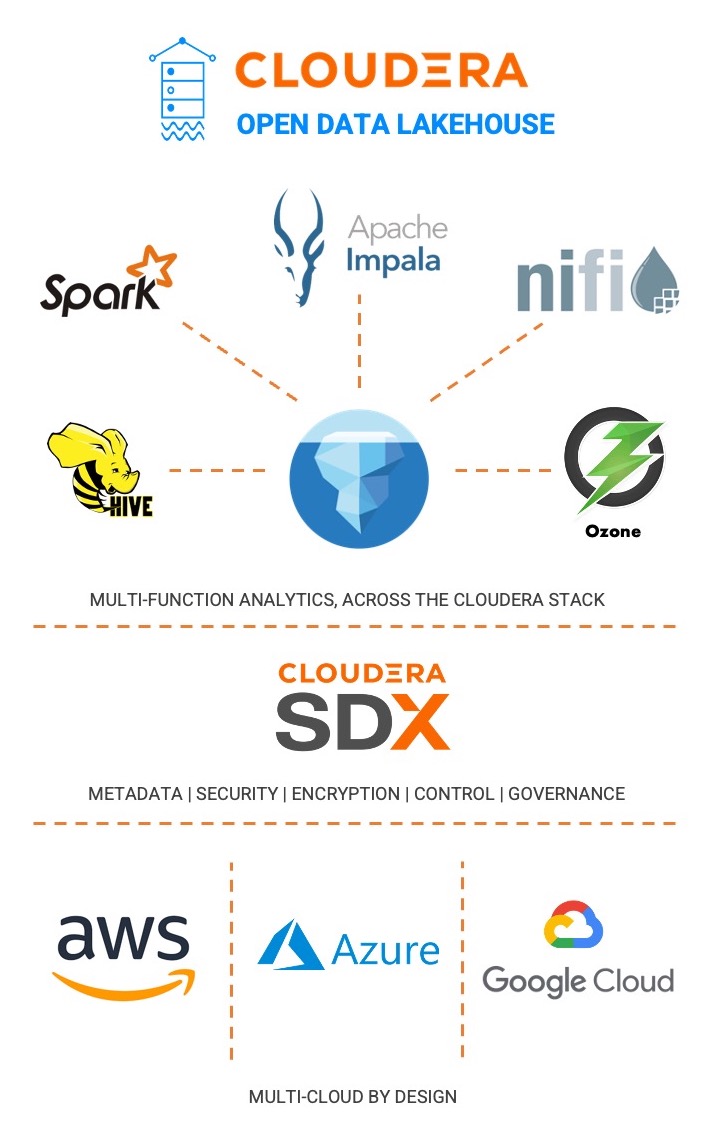
Going from Template to Flow in 5 Minutes with NiFi and Iceberg
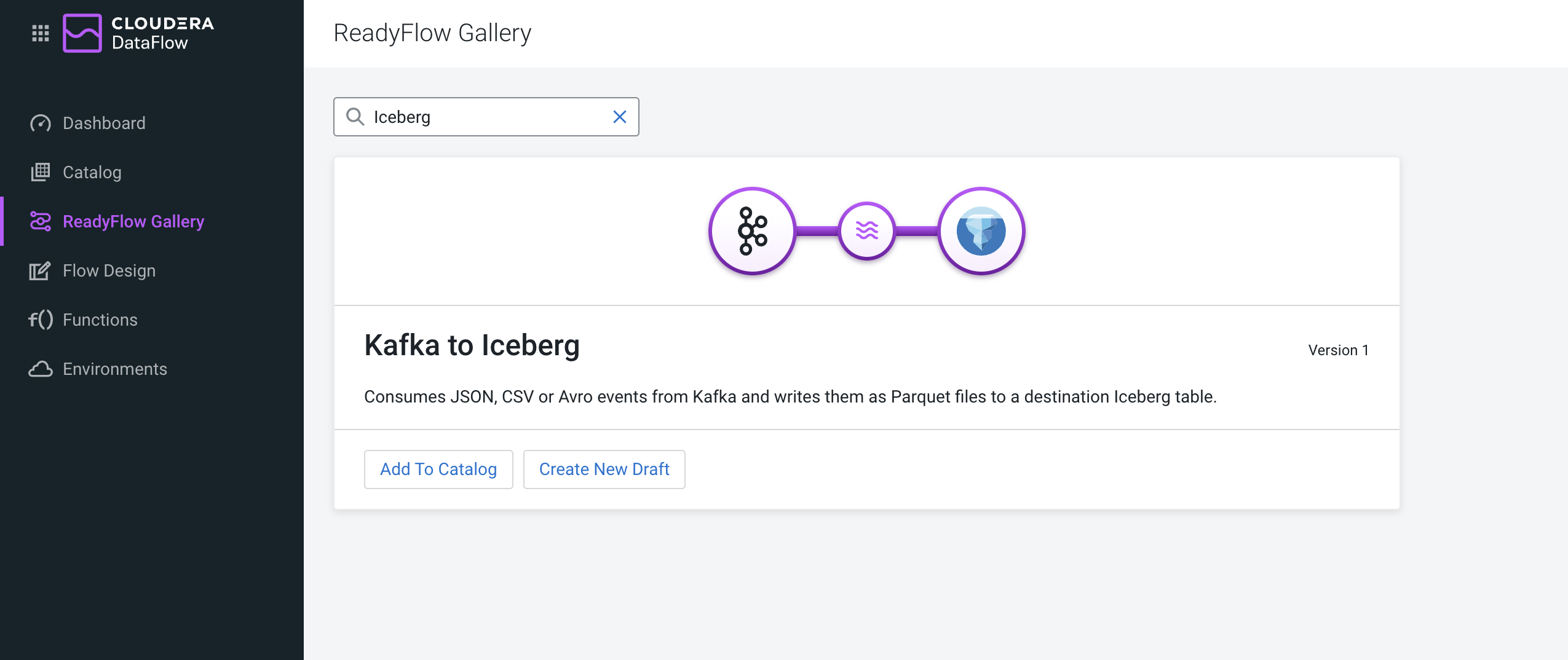
One of the great advantages in the Cloudera product stack are its pre-baked tooling. In the context of NiFi, this means the client is able to select from a number of source to destination flows that enable them to get up and running quickly. For example, if you want to get up and running with a Kafka to Iceberg flow, or S3 to CDW flow, there is a template for either of these. In fact, there are over 30 templates that you can choose from for pointing data source A to data destination B, and have a flow up and running in no time.
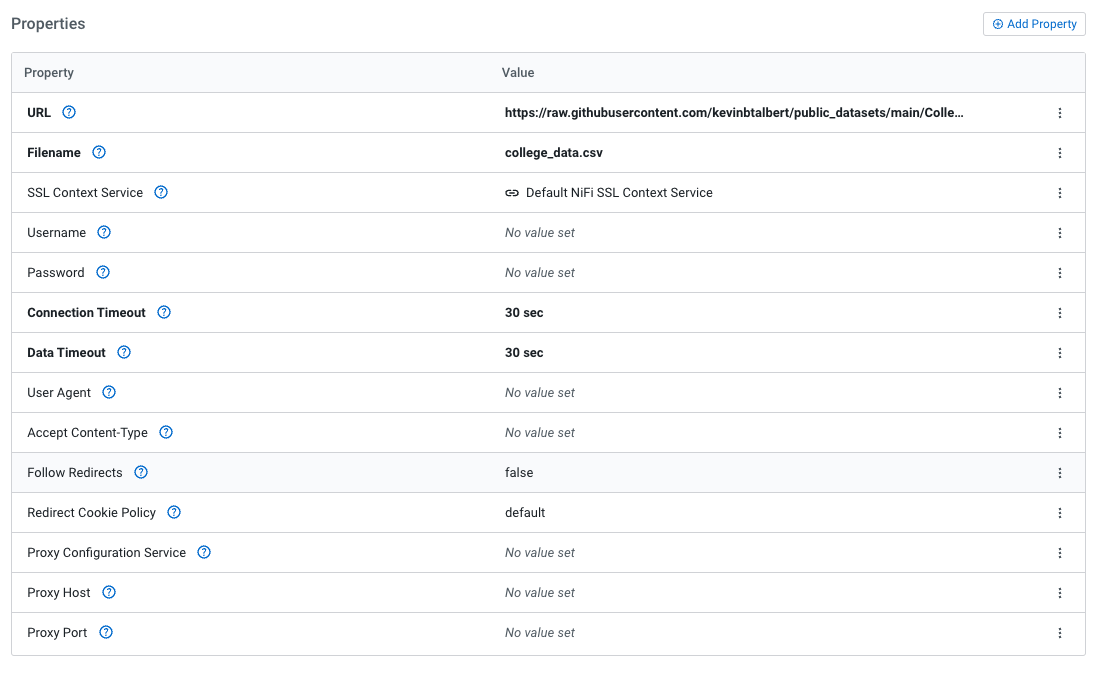
Here I am choosing to use a Kaggle sample dataset that I copied over to my github for easy access. Really a CSV is probably underselling the capabilities of Data Flow here but its an easy starter to get to the Iceberg table that I want to illustrate.
To begin, I grabbed the Kafka to Iceberg ReadyFlow template and jumped in to the designer.
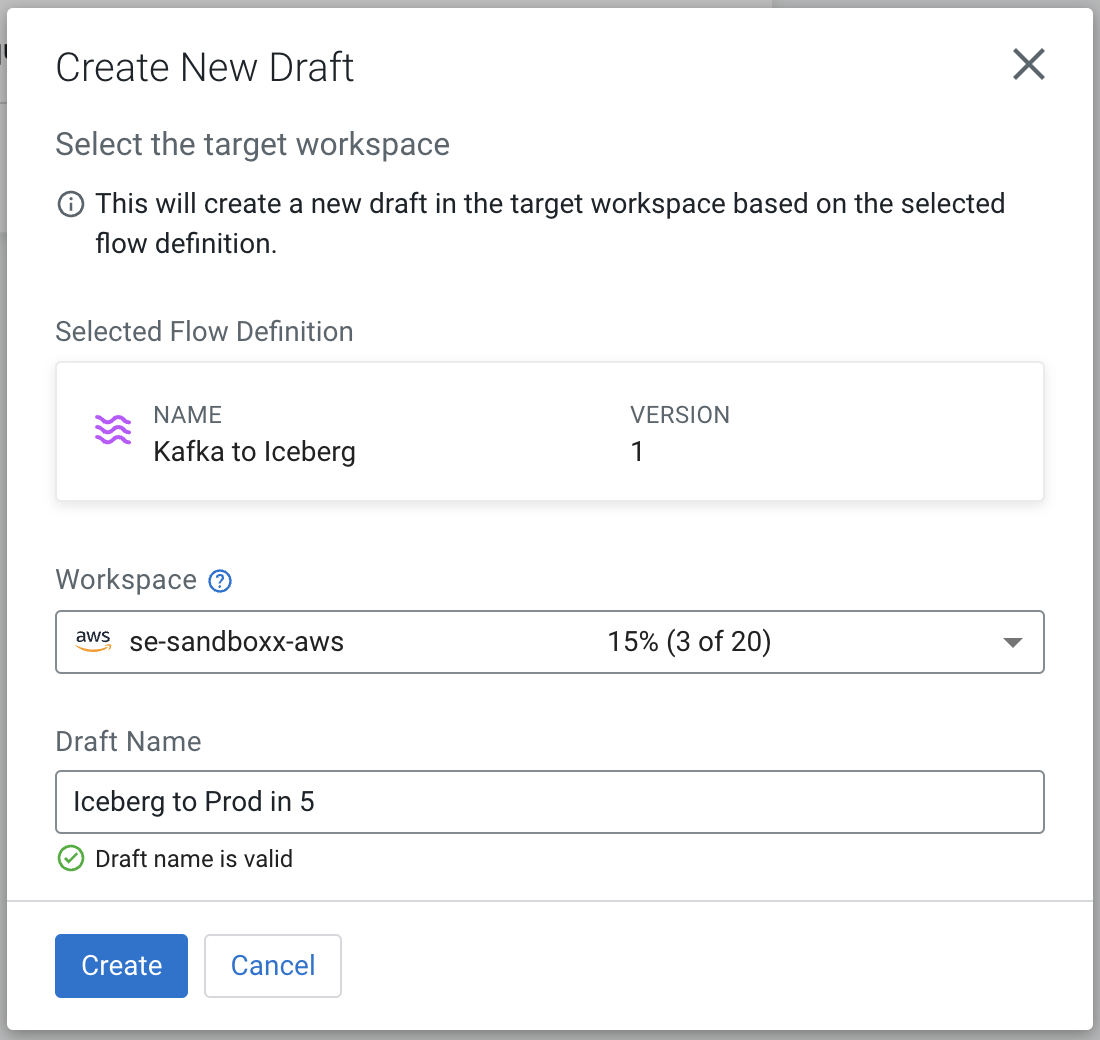
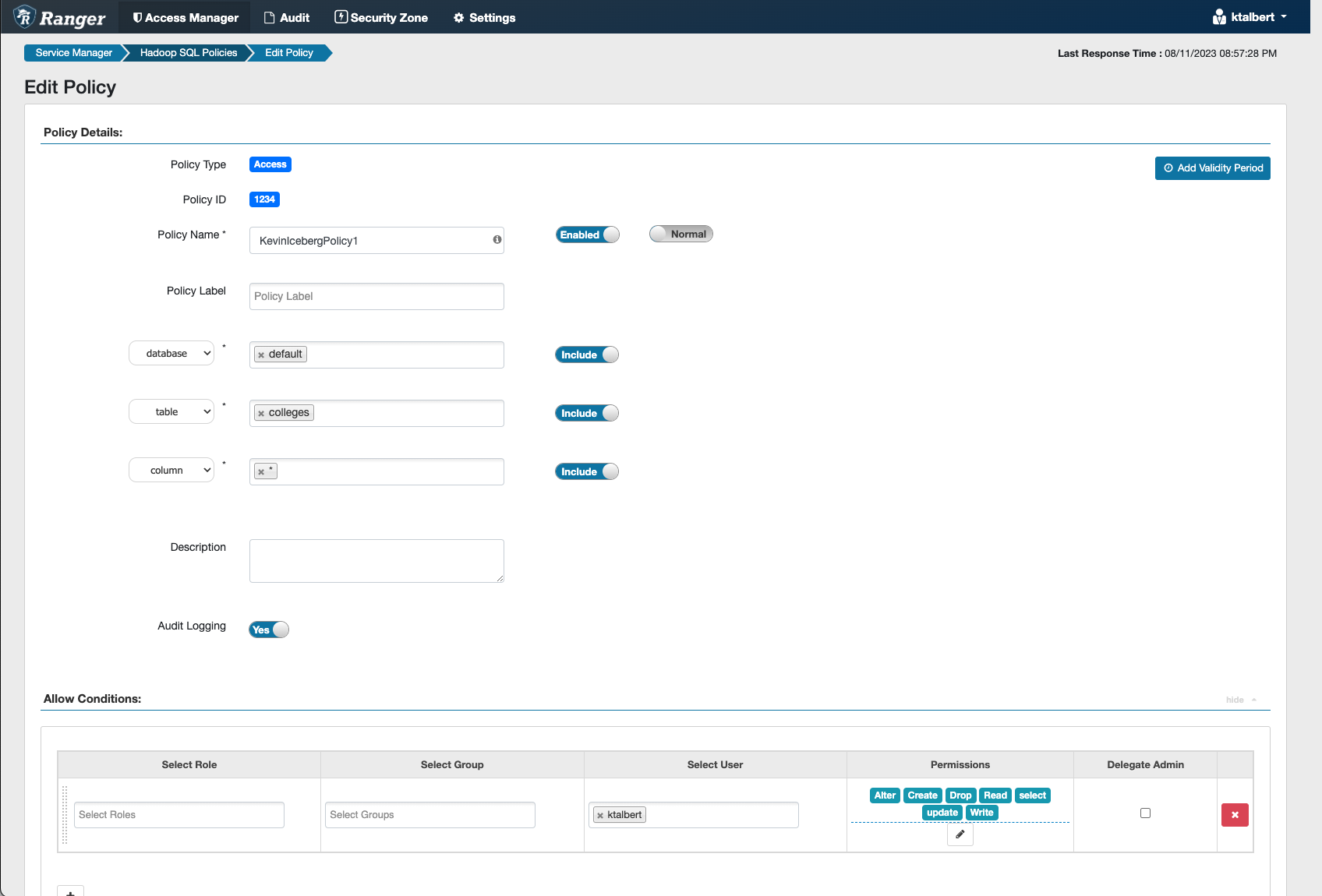
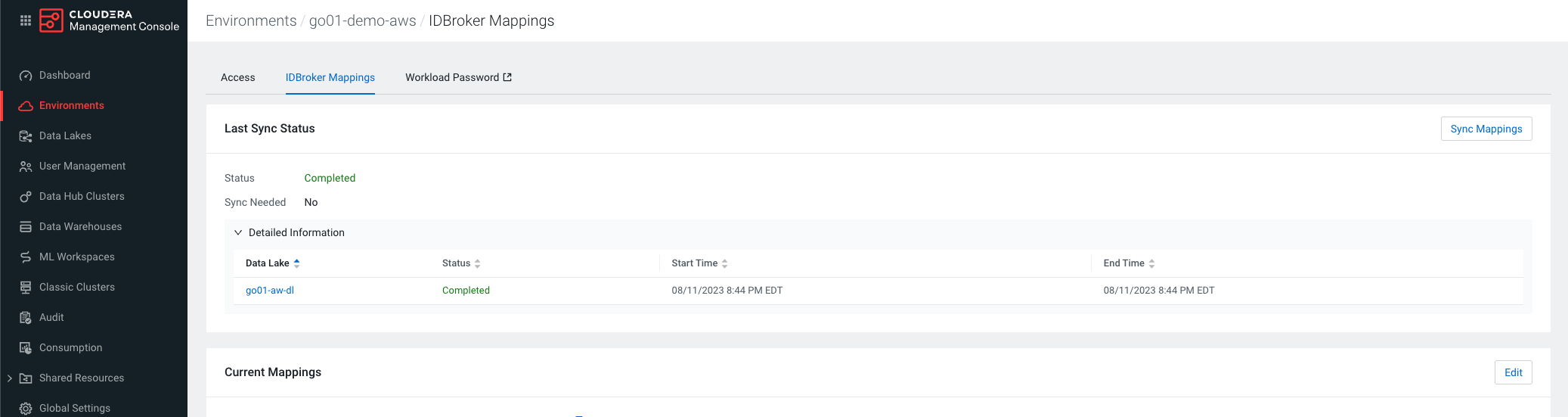
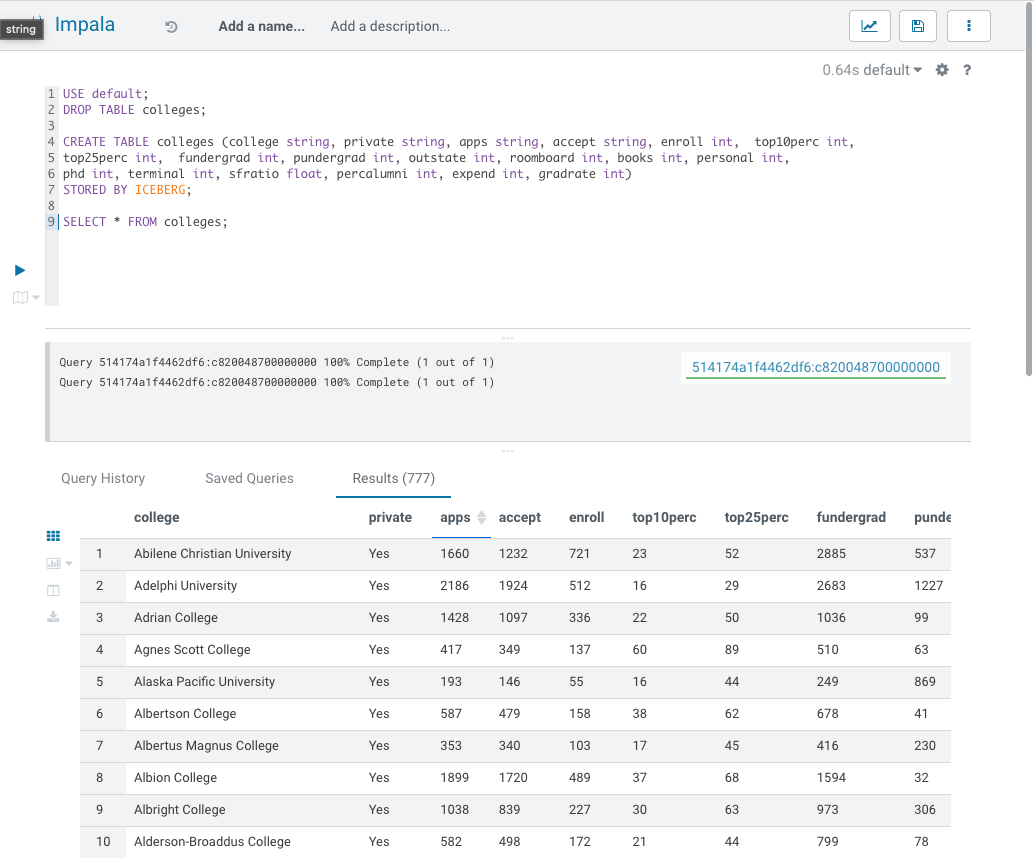
Using the following SQL, I set up my Iceberg table in Cloudera Data Warehouse (CDW), and ensured the necessary Ranger policies and IDBroker Mappings were setup and synced for a successful flow.
USE default;
CREATE TABLE colleges (college string, private string, apps string, accept string, enroll int, top10perc int,
top25perc int, fundergrad int, pundergrad int, outstate int, roomboard int, books int, personal int,
phd int, terminal int, sfratio float, percalumni int, expend int, gradrate int)
STORED BY ICEBERG;
The final flow successfully transfered the data into the Iceberg table “colleges” with the inferred schema that the GetHTTP and PutIceberg processors read.
Note that the processors show the red X beside their status indicating that these have been stopped. This is because I am sourcing constant data through the GetHTTP processor, and hence only want to run the processor once. After running once, the flow stops.
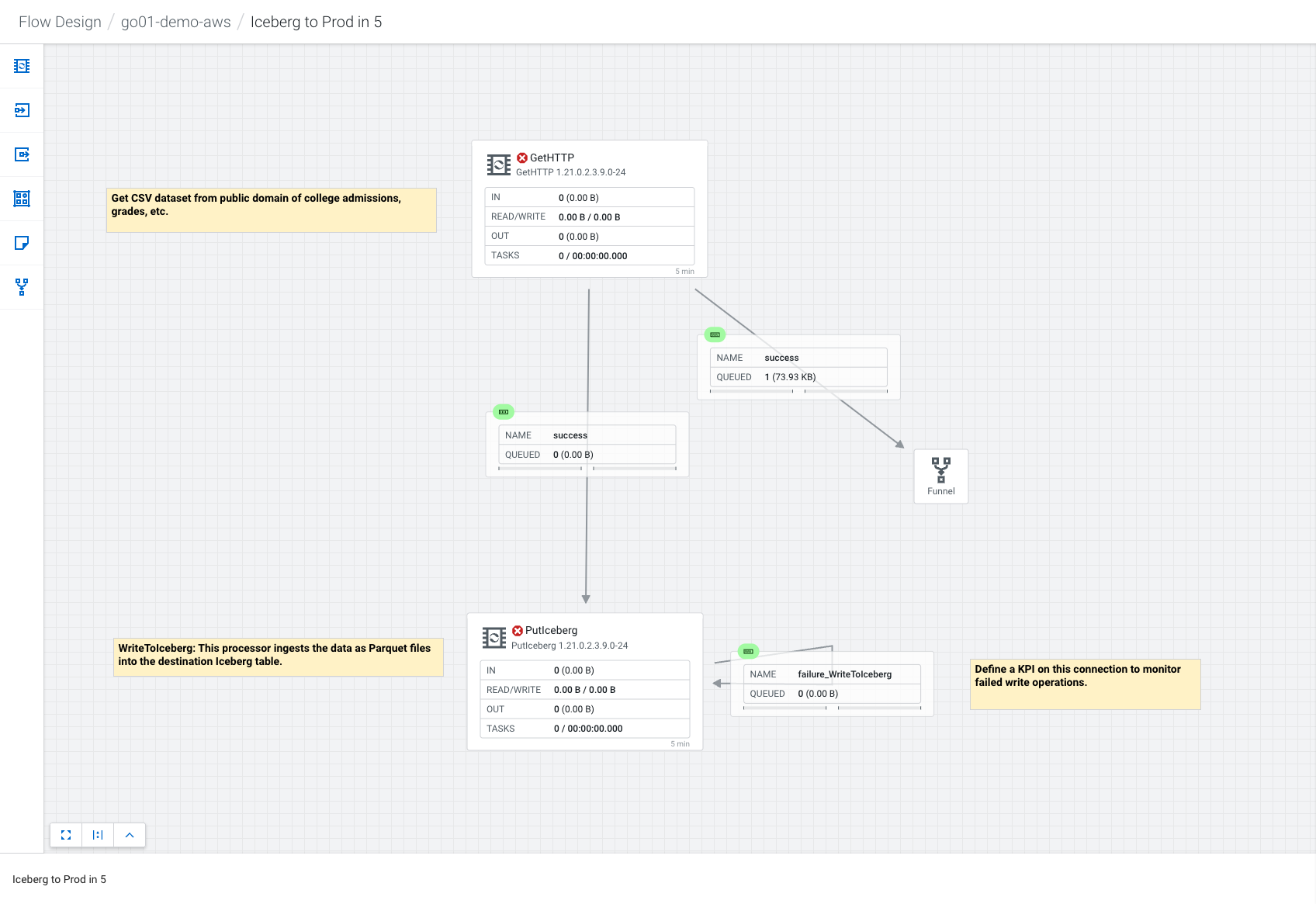
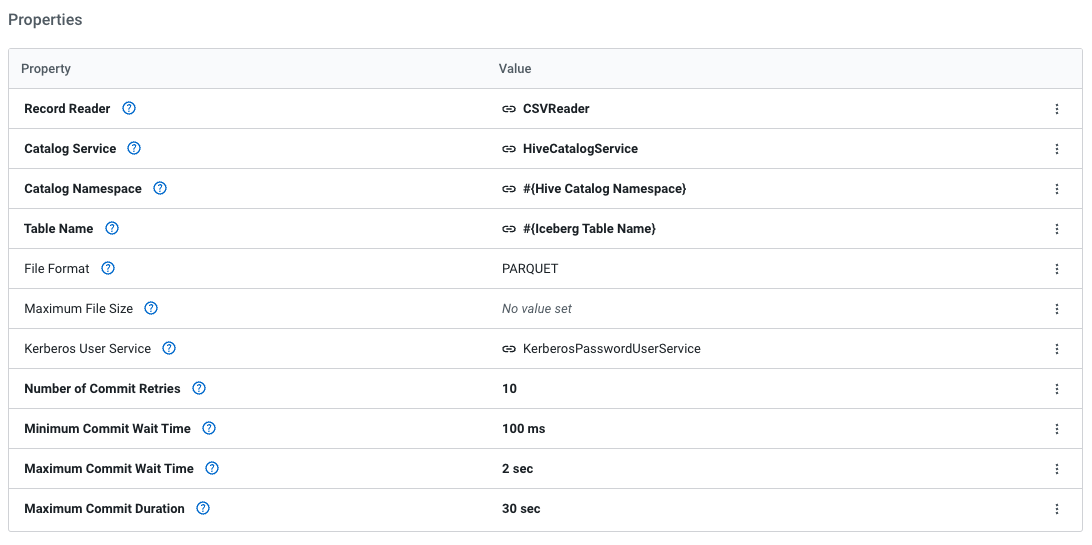
As you do the flow, you may find the following configurations helpful. While most are standard with the ReadyFlow template, you do need to make sure you have set up a Workload Password in the environment you are working in, and that your parameters (such as the CDP Workload User and Password fields) are set.
Configurations: Parameters for the Flow | Enabled Services
Processor Settings: GetHTTP Processor | PutIceberg Processor
Take Your NiFi Flow to the Next Level
Expanding your data flows within the context of an open data lakehouse architecture using NiFi involves a strategic approach, and not all flows are the same. First, identify the diverse data sources feeding into your architecture. Leverage NiFi’s processors to handle different data formats and protocols, ensuring seamless ingestion. Incorporate transformation processors for data enrichment and cleansing, enhancing the quality of incoming data.
Establish a structured flow management strategy. Utilize NiFi’s ability to create complex branching and merging points, allowing you to route data based on conditions or business rules. This can optimize data distribution and processing.
To facilitate integration with the open data lakehouse architecture, leverage NiFi’s compatibility with Iceberg tables. Design your flows to not only ingest data but also interact with Iceberg tables, enabling efficient querying and updates.
Security is paramount in data management. NiFi provides robust security features, enabling encryption, authentication, and access control at various stages of your flows. This ensures the integrity and privacy of your data.
Monitoring and optimization play a critical role. Utilize NiFi’s built-in reporting and monitoring tools to keep track of flow performance. By analyzing these metrics, you can identify bottlenecks and optimize your flows for better efficiency.
Lastly, stay flexible. As your architecture evolves, NiFi’s drag-and-drop interface lets you adapt flows quickly. Integrate new sources, adjust transformations, and accommodate schema changes in Iceberg tables without disruption.
Incorporating these principles, you can create intricate and adaptable data flows with NiFi within the context of an open data lakehouse architecture, effectively harnessing its capabilities for managing complexity while ensuring data integrity and accessibility.
Want to Read More and Get Started?
If any of the features I discussed sound interesting to you, I would encourage you to check out the links below and get hands on. Additionally, if you have not read my article last week, I hope you’ll take some time to read it and see how Iceberg provides valuable capabilities that set it apart from other engines in the big data space today.
Cloudera offers an in-depth documentation to setting up your own Iceberg data flow with Cloudera Data Flow: Ingesting data into CDW using Iceberg table format If this is your first time building a NiFi flow, I highly encourage you to take a look at it as it captures the essence of an end-to-end NiFi flow with discussion of the various configuration changes you may need to set.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}