
Zero to LLM: Deploy an LLM in Under 5 Minutes
In this article, I delve into the significance of Large Language Models (LLMs) in the field of computing and big data, explaining their core functioning through neural networks like transformers. I provide code examples using pre-trained BERT-based LLMs for question-answering and introduce a Cloudera Machine Learning (CML) Applied ML Prototype (AMP) that leverages open-source LLMs to build a ChatBot augmented with semantic search. I include technical details on the AMP’s architecture, tech stack, and how to get started with Hugging Face’s transformers library for various natural language processing tasks.
Understanding the Significance of LLMs on Big Data
LLMs, or “Large Langauge Models”, have become such common vernacular in the computing and big data space that their significance to the broader machine learning ecosystem of models, development tools, and end user applications may have become convoluted, and at least understated. LLM models come in a variety of flavors but at their core, they are an advanced AI designed to understand and produce human language. While perhaps this is an oversimplification, under the hood, the LLM relies on a neural network architecture known as a transformer which will predict the next word in the sentence. The term “large” is indicative of the immense scale of the parameters input to the model (sometimes trillions). The models can be generative, foundation, or open-source and the decision of which one to use relies on the developer or data analyst’s use case. LLMs can be used for general tasks or specific tasks such as code generation, language translation, sentiment analysis, data analysis, and the like. The former, general tasks, is often represented through a chatbot, and will be the basis of a content generation model we build today using Cloudera’s Machine Learning application.
Getting Started With a Pre-Trained BERT-based LLM
In the below example, I illustrate how you can leverage a pre-trained BERT-based LLM to get an answer to a question. Note that I have provided context which adds a layer of accuracy to the result. For example, if I asked about “Iceberg”, the model may respond with a discussion about the type of lettuce or chunk of ice from a glacier and not the Apache Iceberg project I wanted to know more about. This code is built on the BERT model and assumes you pip install the libraries torch and transformers.
from transformers import BertForQuestionAnswering, BertTokenizer
import torch
# Load pre-trained BERT model and tokenizer
model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"
model = BertForQuestionAnswering.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
# Define context and question
context = '''Cloudera Machine Learning optimizes ML workflows across your business with native
and robust tools for deploying, serving, and monitoring models. With extended SDX for models,
govern and automate model cataloging and then seamlessly move results to collaborate across
CDP experiences including Data Warehouse and Operational Database.'''
question = "What does Cloudera Machine Learning do"
# Define encoding
encoding = tokenizer.encode_plus(text=question,text_pair=context)
# Token embeddings
inputs = encoding['input_ids']
# Segment embeddings
sentence_embedding = encoding['token_type_ids']
# Input tokens
tokens = tokenizer.convert_ids_to_tokens(inputs)
# Create output model
output = model(input_ids=torch.tensor([inputs]), token_type_ids=torch.tensor([sentence_embedding]))
start_index = torch.argmax(output.start_logits)
end_index = torch.argmax(output.end_logits)
answer = ' '.join(tokens[start_index:end_index+1])
# Print model result
print(answer)
When I ran the model for the question “What does Cloudera Machine Learning do”, I got the result: “optimizes ml workflows across your business”. You may want to provide your own context and question and try this yourself. The code is in my GitHub here.
Leveraging AMPs in Cloudera Machine Learning
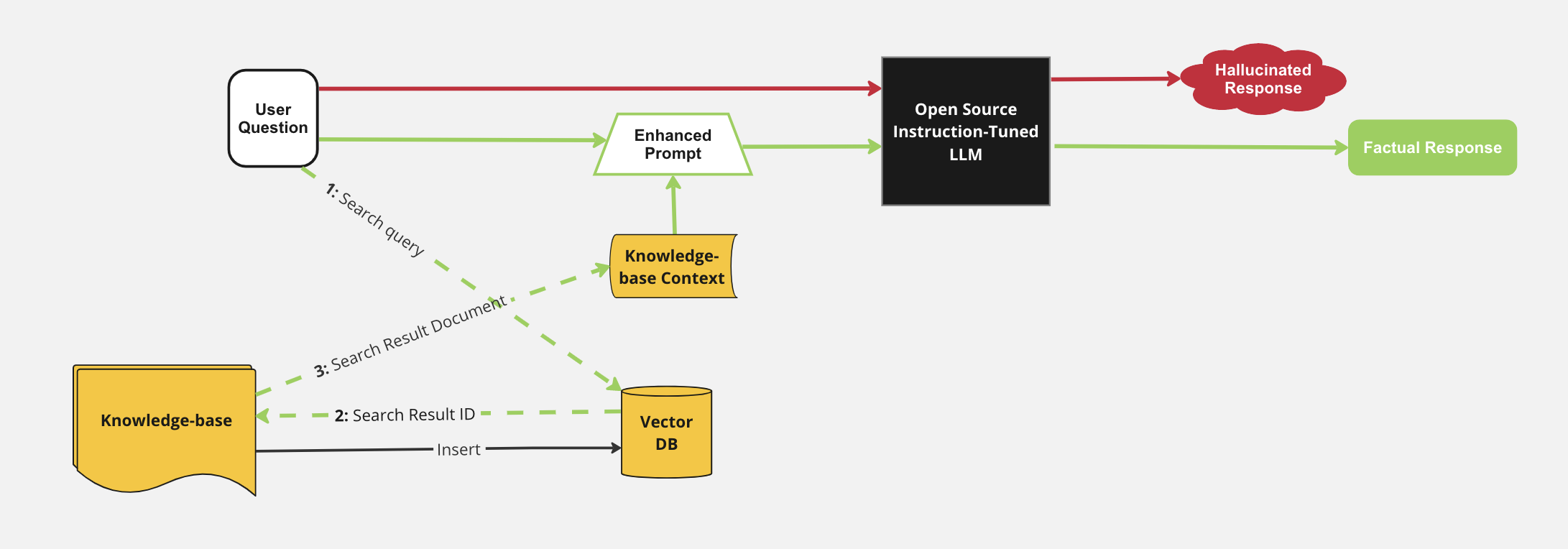
So you get the Python and want to jump into the big leagues? The next example which leverages an “AMP” (Applied ML Prototypes) in CML called LLM Chatbot Augmented with Enterprise Data allows the user to take advantage of an open-source, pre-trained, instruction-following LLM to create a web-based ChatBot, improving its responses with contextual information from an internal knowledge base obtained through semantic search using an open source Vector Database. I included the “RAG” Architecture, or “Retrieval Augmented Generation” Architecture below as well, taken from the GitHub linked above and here because I think it illustrates the flow by which a factual response is generated from a provided context/knowledge base. Though the idea of Cloudera’s AMPs are to abstract this interaction and provide the user with value quickly, I think the curious data scientist would find the underlying process interesting as I did.
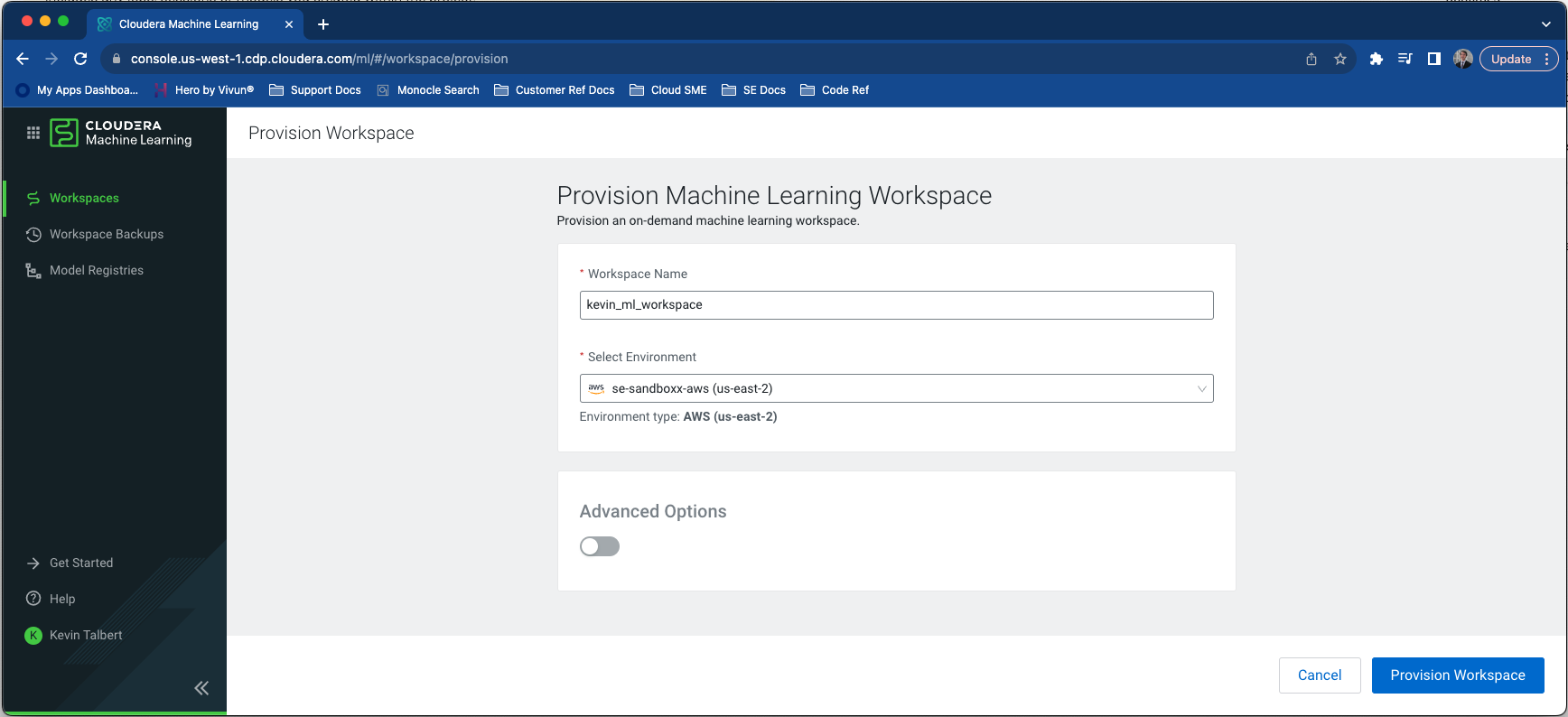
To get started, you’ll want to provision a machine learning workspace in CML in an environment with available CPU/GPUs. The project can be customized as well to use a different editor, kernel, etc. but I choose to accept the defaults. (Spark is not required for this AMP.)
 View Larger
View Larger
 View Larger
View Larger
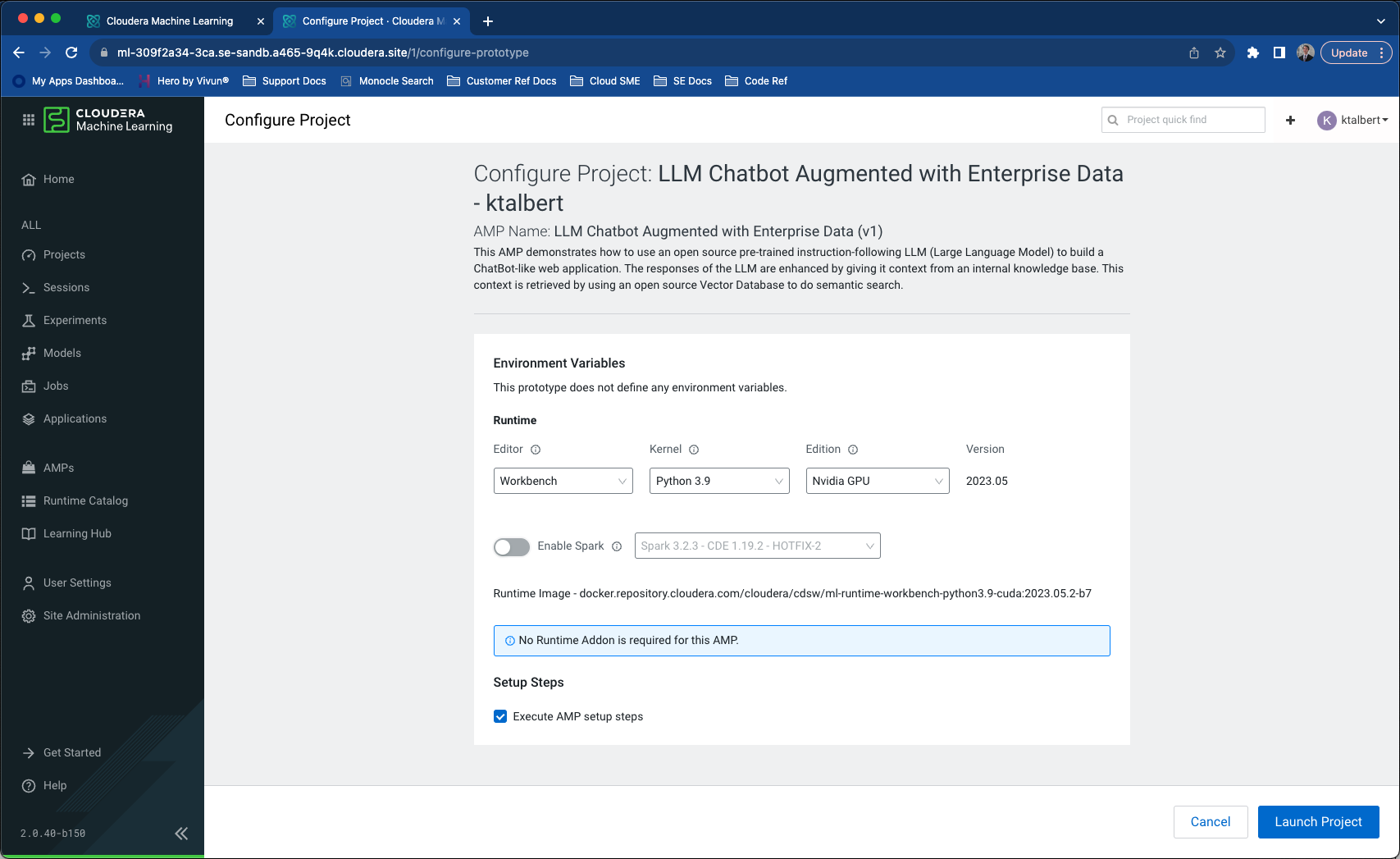
After the AMP finishes building (there are 8 steps which could take some time to run, depending on CPU/GPU availability), the user can add their own knowledge base to the data/ directory over the existing data there. If you add additional data to that directory after setting up the AMP, you’ll need to run the “Populate Vector DB with document embeddings” again.
The project will show a successful creation with a link to open the Gradio site hosting the chatbot.
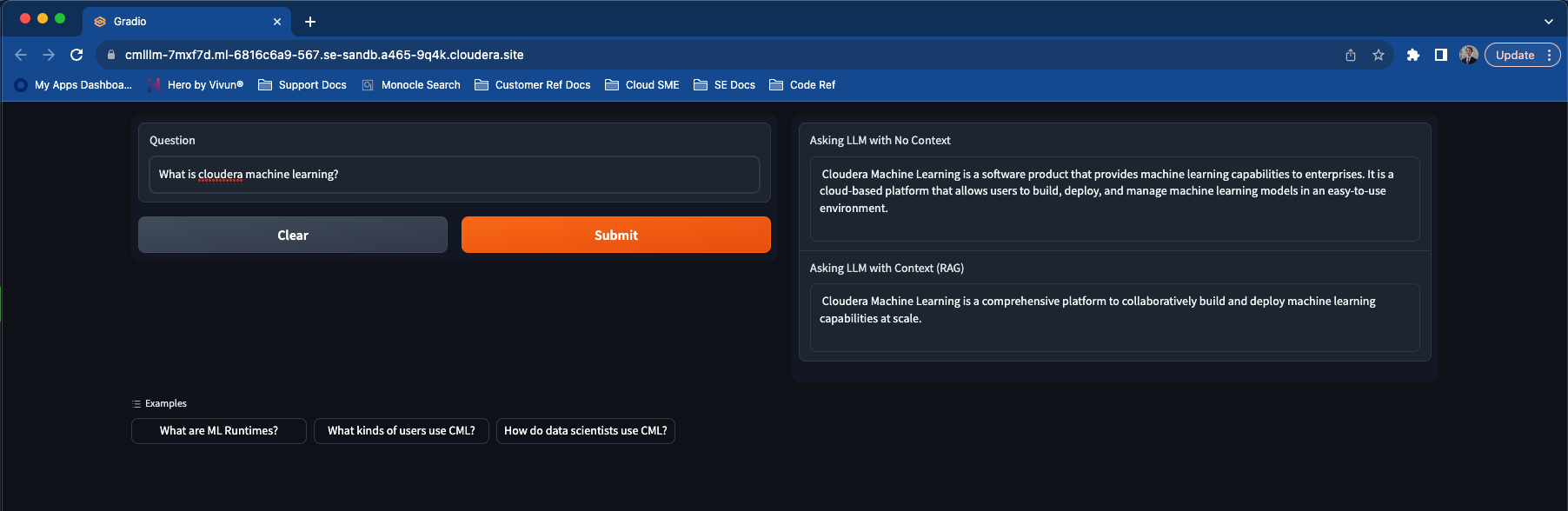
The LLM Chatbot Augmented with Enterprise Data is built on the all-MiniLM-L12-v2 vector embeddings generation model, the h2ogpt-oig-oasst1-512-6.9b instruction-following large language model, and the Hugging Face transformers library. The vector database is handled by Milvus and the chat front end website by Gradio.

Want to Read More and Get Started?
As you may be able to imagine, the use cases here are really endless. Automated document summarization, legal and compliance research, technical support chatbots, competitive intelligence, social media monitoring, and even BI queries or translation services are just a few of the ways LLMs provide incredible value to organizations. The value add that CML offers is that your proprietary data never has to leave your organization; you build on an existing knowledge base to curate your own internal “repository of information”, driven by the context of your organization’s domain of knowledge.
If any of the features I discussed sound interesting to you, I would encourage you to check out the links below and get hands on. Hugging Face has an incredibly popular open source ML tooling community with a large set of transformers for PyTorch (like I used) and TensorFlow. Their GitHub has an expansive set of demos in NLP, computer vision, and a host of other tasks: Hugging Face GitHub. Additionally, if your company or organization has use cases that you feel could be solved through CML, I would be happy to spend some time going through this with you and discuss how you can take advantage of a CDP Public Cloud trial to get hands on with this tech.

{kind=link}